


This tutorial will show you how to use MindsDB to forecast rainforest degradation by predicting forest fires in the Amazon rainforest.
Introduction
MindsDB is a SQL-based tool that can be used to create and train time-series machine learning models directly from your database. With MindsDB, data teams and data analysts can use their data to build, train, optimize, and deploy machine learning models that provide meaningful insights for real-world problems.
The Amazon rainforest is a tropical rainforest in the Amazon biome that covers territory belonging to nine nations. As the only large forest still standing, the Amazon rainforest can create its own weather and influence climates around the world. Sadly, this delicate ecosystem is constantly threatened by deforestation and fires (caused by natural and anthropogenic factors).
With MindsDB, historical data from any part of the world can be turned into future insights. This tutorial will show you how to use MindsDB to create a machine-learning model that provides insight into the Amazon rainforest’s degradation by predicting forest fires using a historical dataset from Kaggle.
Setup
This tutorial will show you how to use MindsDB to create a time series sales forecasting machine learning model using sales data from Brazil that was recorded on a day-to-day basis from 2014–2016.
If you’d like to follow this tutorial, you can use the MindsDB Cloud Editor (create your free MindsDB Cloud account here) to create and train your time series prediction model. You may also download the dataset we will be using, ‘inpe_brazilian_amazon_fires_1999_2019.csv’ from Kaggle.
Checckout this video to learn how to create a free account with MindsDB:
STEP 1 — Import your data
Visit the MindsDB Cloud Editor in your browser and click, ‘Add Data’.

Next, select the “Files” tab.

Click on “Import File” to upload the .csv file from your device. (Note: Make sure to name the table using underscores instead of spaces.)

Note: be sure to name your dataset in the proper format
To double-check the .csv file import was successful, simply run this command:
SHOW TABLES FROM files;

(Note: When you upload data files to MindsDB, they are saved in the files directory by default. Be sure to add ***files****.your_file_name* to your SQL commands)
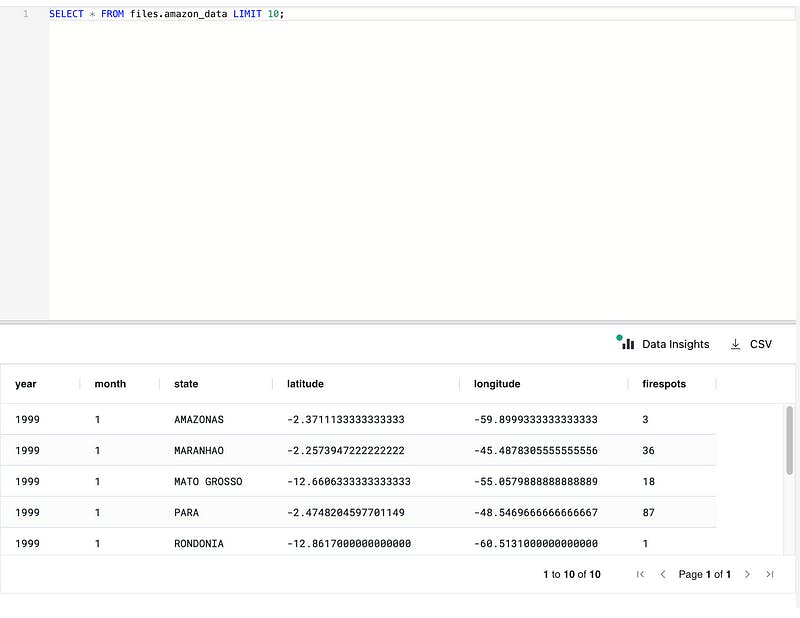
Step 2: Preview Your Data
Now that you’ve imported the dataset, let’s use SQL to preview the contents.
STEP 3: Create Your Predictor Model
Now that we’ve imported our data, we can start using it to train our predictor. Let’s start by creating our predictor model using the MindsDBCREATE PREDICTOR method.
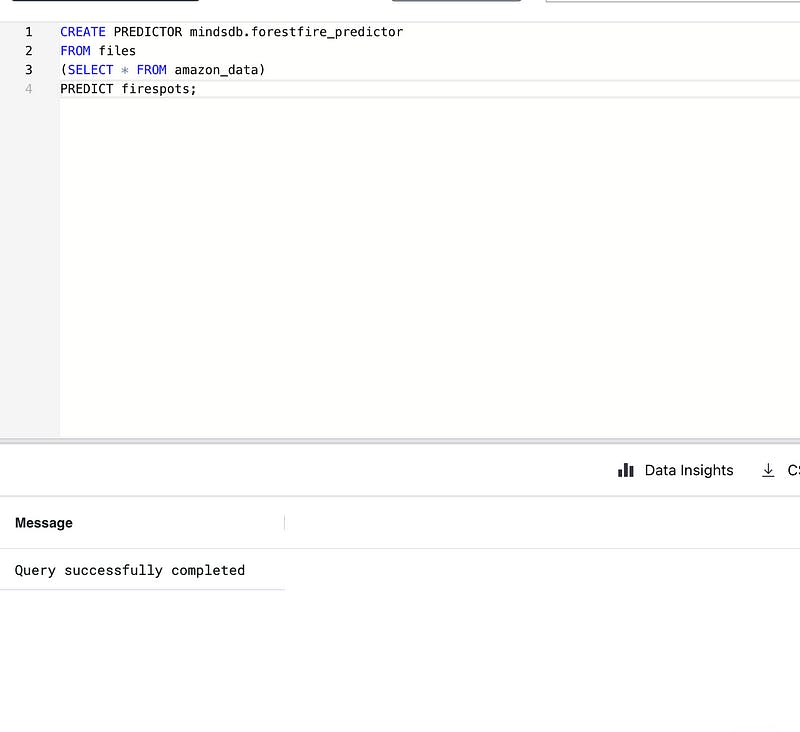
Make sure you don’t get any errors in your output here, as this may mean your predictor was not created properly.
STEP 4: Check the Status of the Predictor Model
Before we go any further, let’s check the status of our predictor:
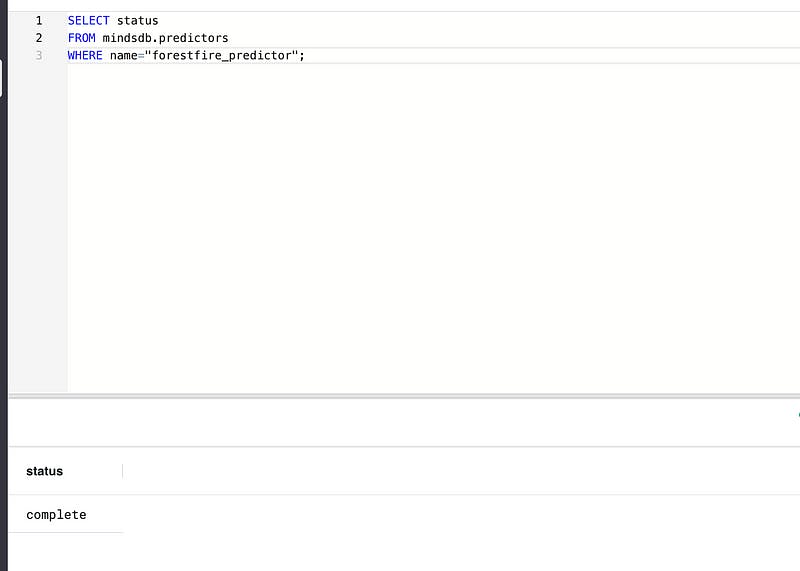
If you run this command and the output reads, “training”, it means your model is still training. Give it a few minutes and run the command again. Do not proceed until your output reads **complete!**
If you find the output continually reads, “generating” you may have an error in your ***CREATE PREDICTOR***syntax.
STEP 5: Start Making Predictions
Now that we’ve trained your predictor model, we can start getting insights about future forest fires.
To begin, let’s test our predictor by inputting a date that is included in the dataset:

Looks good. The outputted firespots number is consistent with the average number of firespots in the year 2000.
Let’s add some more variables and see what the predictor outputs for the year 2019 in the state region, “Para”:
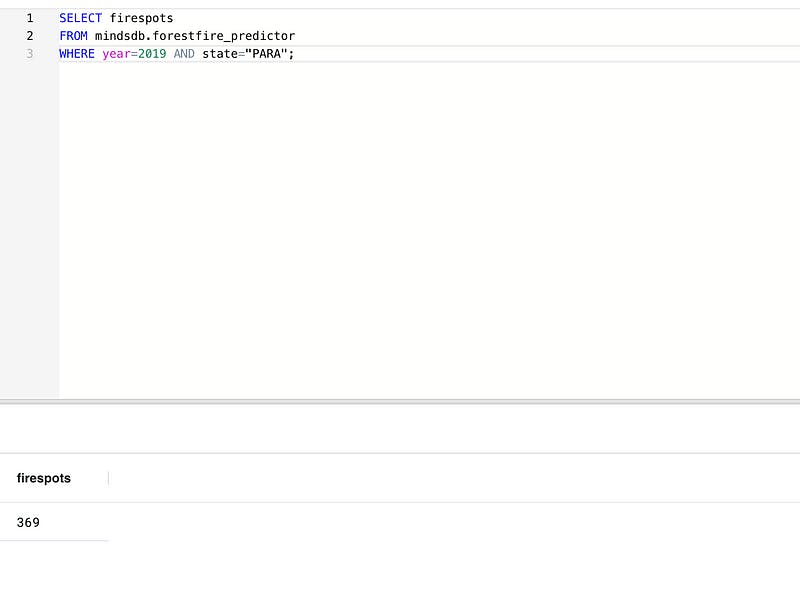
Nice. We know from our data that there were more fires that year and in that region, so our predictor is doing well
Let’s see about firespots in ACRE for the year 2020, which is not included in this dataset:

As the dataset shows, fires decreased drastically in ACRE in 2019, so this is a great prediction for 2020 (which is not included in this dataset).

Now, let’s hone in on one region, Amazonas, and query the dataset for 3 different years (2001, 2010, 2030).
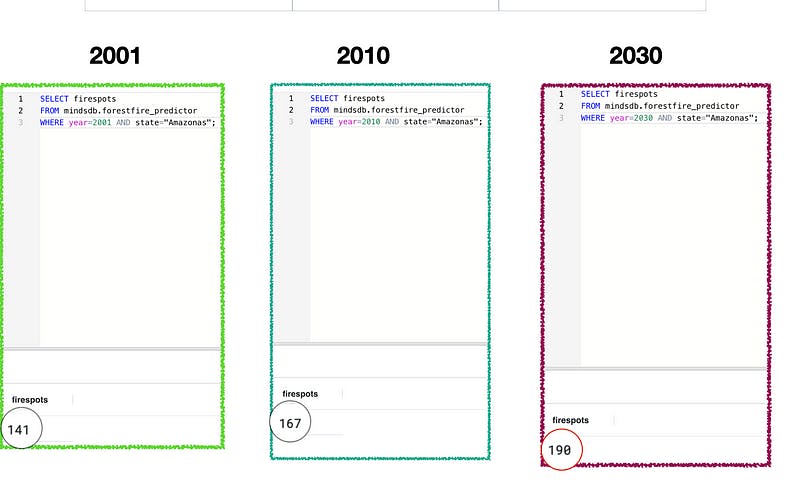
In the image above, we queried the dataset to return the number of fires in Amazonas in 2001 and 2010. Then, we asked it to predict the number of firespots in Amazonas in the year 2030. As we can see, the amount of fires is increasing with time, so it’s no surprise our predictor is outputting 190 for the year 2030.
CONCLUSION
As can be seen in this tutorial, MindsDB makes machine learning simple, intuitive, and highly effective!
Do you have something interesting you’d like to forecast? Head to MindsDB and start training your model today!
Want to learn more about MindsDB? Check out my YouTube video: